Saliency explanations on ODH
This tutorial will walk you through setting up and using TrustyAI to provide saliency explanations for model inferences within a OpenShift environment using OpenDataHub. We will deploy a model, configure the environment, and demonstrate how to obtain inferences and their explanations.
|
Since TrustyAI explanations are not yet supported at the ODH Dashboard level, we will use the command line to interact with the models and TrustyAI service throughout this tutorial. |
Setup
Install OpenDataHub and model server
Start by setting up OpenDataHub using the installation guide provided in the project documentation. You can find the installation instructions here: OpenDataHub Installation Guide.
-
Create a new namespace specifically for your explainer tests. This isolates your resources from other deployments. We will refer to this namespace as
$NAMESPACEthroughout the tutorial.export NAMESPACE="explainer-tests" oc new-project $NAMESPACE -
Label your new namespace to enable ModelMesh.
oc label namespace $NAMESPACE modelmesh-enabled=true --overwrite -
Deploy the serving runtime environment required for your models. We will be using an sklearn model. An example serving runtime can be found at odh-mlserver-1.x.yaml.
oc apply -f odh-mlserver-1.x.yaml -n $NAMESPACE -
Apply the necessary storage configuration for ModelMesh. This could be an empty config such as
apiVersion: v1 kind: Secret metadata: name: storage-configoc apply -f storage-config.yaml -n $NAMESPACE
Deploy the Model and Service
The model used for this example is an XGBoost regression model for the California Housing Dataset[1] which aims at predicting a house’s price (in $100k units) based on some household characteristics. Namely
-
MedInc, median income in block group -
HouseAge, median house age in block group -
AveRooms, average number of rooms per household -
AveBedrms, average number of bedrooms per household -
Population, block group population -
AveOccup, average number of household members -
Latitude, block group latitude -
Longitude, block group longitude-
Let’s start by deploying the model you want to use for the explanations. Ensure the model configuration is correctly set in the
is-housing.yamlfile.apiVersion: serving.kserve.io/v1beta1 kind: InferenceService metadata: name: housing annotations: serving.kserve.io/deploymentMode: ModelMesh spec: predictor: model: modelFormat: name: xgboost runtime: mlserver-1.x storageUri: "https://github.com/trustyai-explainability/model-collection/raw/housing-data/housing-data/model.json"oc apply -f is-housing.yaml -n $NAMESPACE -
Deploy the TrustyAI service, which will be used to obtain explanations.
apiVersion: trustyai.opendatahub.io/v1alpha1 kind: TrustyAIService metadata: name: trustyai-service spec: storage: format: "PVC" folder: "/inputs" size: "1Gi" data: filename: "data.csv" format: "CSV" metrics: schedule: "5s"oc apply -f trustyai-cr.yaml -n $NAMESPACE -
Check the status of the pods to ensure everything is running as expected.
oc get pods -n $NAMESPACEYou should expect to see the following pods running:
-
NAME READY STATUS RESTARTS AGE
modelmesh-serving-mlserver-1.x-7b89657544-45h89 5/5 Running 0 34m
modelmesh-serving-mlserver-1.x-7b89657544-rf8qq 5/5 Running 0 34m
trustyai-service-7895cbc447-wqrpf 2/2 Running 0 34mYou can now make a note of the TrustyAI’s pod name for future reference. We will also take the opportunity to get the model’s and the TrustyAI service’s route full URLs as well as the required authentication token.
export TRUSTYAI_POD=$(oc get pods -n $NAMESPACE | grep trustyai-service | awk '{print $1}')
export MODEL_ROUTE=$(oc get route explainer-test -n $NAMESPACE -o jsonpath='{.spec.host}')
export TRUSTYAI_ROUTE=$(oc get route trustyai-service -n $NAMESPACE -o jsonpath='{.spec.host}')
export TOKEN=$(oc whoami -t)
export MODEL="housing"Requesting Explanations
Request an inference
In order to obtain an explanation, we first need to make some inferences. The explanation request will be based on the ID of an existing inference.
The file explainer-data-housing.json contains a set of datapoints you can send to the model. Replace ${TOKEN} with your actual authorization token.
curl -skv -H "Authorization: Bearer ${TOKEN}" \
https://${MODEL_ROUTE}/v2/models/${MODEL}/infer \
-d @explainer-data-housing.jsonYou can now verify that you have 1000 observations in TrustyAI’s storage:
curl -sk -H "Authorization: Bearer ${TOKEN}" \
${TRUSTYAI_ROUTE}/info | jq '.housing.data.observations'Let’s assume that inferences that result in highest and lowest predicted house prices are respectively:
+
{
"inputs": [
{
"name": "inputs",
"shape": [
1,
8
],
"datatype": "FP64",
"data": [
[
6.6227,
20.0,
6.282147315855181,
1.0087390761548065,
2695.0,
3.3645443196004994,
37.42,
-121.86
]
]
}
]
}+
{
"inputs": [
{
"name": "inputs",
"shape": [
1,
8
],
"datatype": "FP64",
"data": [
[
4.2679,
33.0,
5.7566462167689165,
0.9918200408997955,
1447.0,
2.9591002044989776,
34.68,
-118.14
]
]
}
]
}We will send these payloads to model so we can use them for our explanation.
curl -sk -H "Authorization: Bearer ${TOKEN}" \
-H "Content-Type: application/json" \
${MODEL_ROUTE}/v2/models/${MODEL}/infer \
-d @kserve-explainer-housing-highest.json
curl -sk -H "Authorization: Bearer ${TOKEN}" \
-H "Content-Type: application/json" \
${MODEL_ROUTE}/v2/models/${MODEL}/infer \
-d @kserve-explainer-housing-lowest.jsonGetting an inference ID
The TrustyAI service provides an endpoint to list stored inference ids. You can list all (non-synthetic or organic) ids by running:
curl -skv -H "Authorization: Bearer ${TOKEN}" \
https://${TRUSTYAI_ROUTE}/info/inference/ids/${MODEL}?type=organicThe response will be similar to
[
{
"id":"a3d3d4a2-93f6-4a23-aedb-051416ecf84f",
"timestamp":"2024-06-25T09:06:28.75701201"
}
]Assuming we did no other inference in the meantime, we will extract the two latest inference ID (highest and lowest predictions) for use in obtaining an explanation.
export ID_LOWEST=$(curl -s ${TRUSTYAI_ROUTE}/info/inference/ids/${MODEL}?type=organic | jq -r '.[-1].id')
export ID_HIGHEST=$(curl -s ${TRUSTYAI_ROUTE}/info/inference/ids/${MODEL}?type=organic | jq -r '.[-2].id')Request Explanations
We will use LIME and SHAP as our explainers for this tutorial. More information on LIME can be found here.
Request a LIME explanation for the selected inference ID.
|
The URL of the model server’s service must be specified in the This field only accepts model servers in the same namespace as the TrustyAI service, with or without protocol or port number.
|
echo "Requesting SHAP for lowest"
curl -sk -H "Authorization: Bearer ${TOKEN}" -X POST \
-H "Content-Type: application/json" \
-d "{
\"predictionId\": \"$ID_LOWEST\",
\"config\": {
\"model\": {
\"target\": \"modelmesh-serving:8033\",
\"name\": \"${MODEL}\",
\"version\": \"v1\"
},
\"explainer\": {
\"n_samples\": 75
}
}
}" \
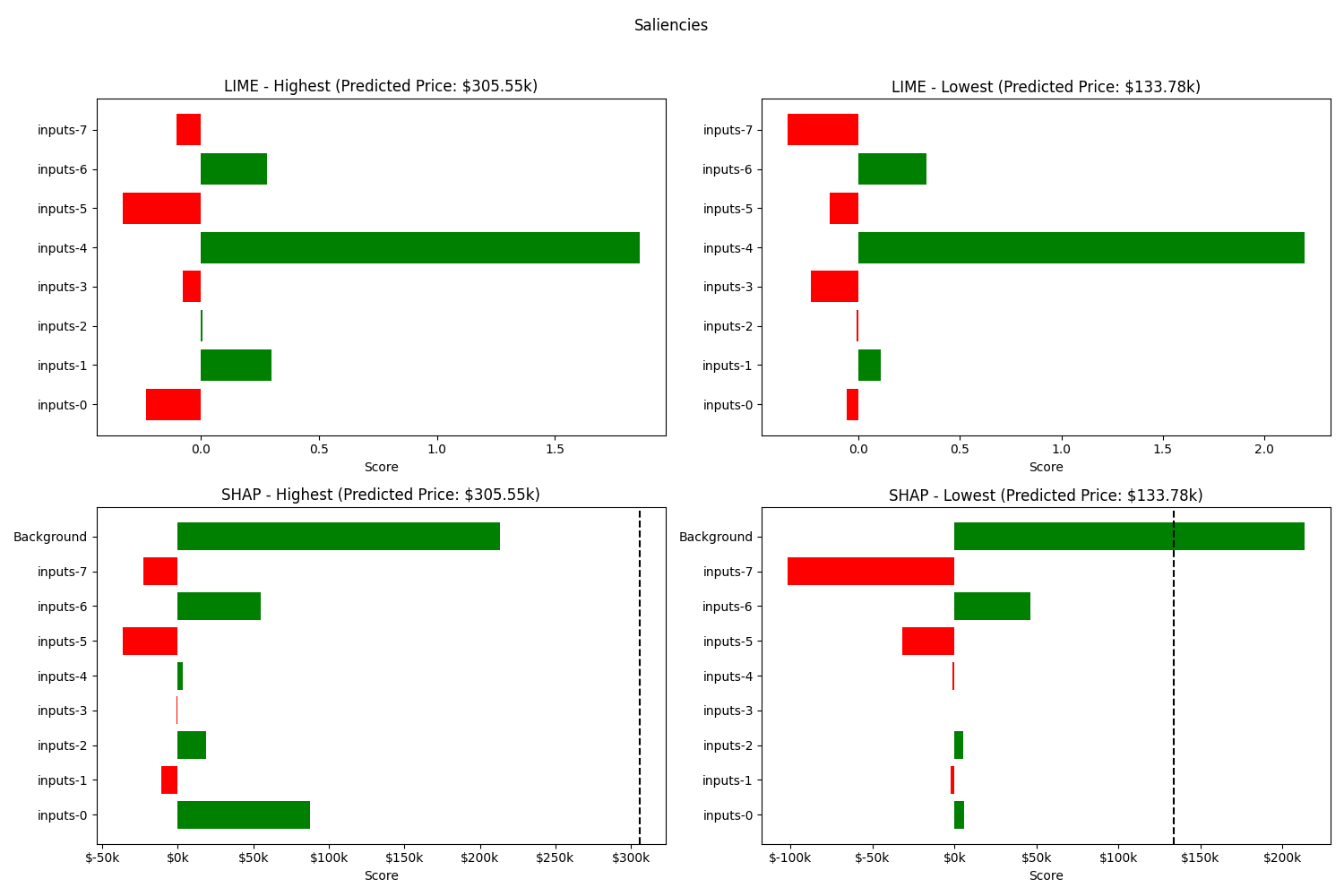
${TRUSTYAI_ROUTE}/explainers/local/shapThe saliency explanation from SHAP should be similar to
{
"timestamp": "2024-07-29T20:47:41.511+00:00",
"type": "explanation",
"saliencies": {
"predict-0": [
{
"name": "inputs-0",
"score": 0.05798290741077758,
"confidence": 0.12904453014228442
},
{
"name": "inputs-1",
"score": -0.02583508910348834,
"confidence": 0.144478542298868
},
{
"name": "inputs-2",
"score": 0.05414353021811688,
"confidence": 0.15250464517451795
},
{
"name": "inputs-3",
"score": -2.9211788608753814E-4,
"confidence": 0.1489221798898736
},
{
"name": "inputs-4",
"score": -0.010685071550586595,
"confidence": 0.13328783125568475
},
{
"name": "inputs-5",
"score": -0.3197132284493354,
"confidence": 0.1341401364621916
},
{
"name": "inputs-6",
"score": 0.4630318848137003,
"confidence": 0.13154033030120849
},
{
"name": "inputs-7",
"score": -1.0172981362310851,
"confidence": 0.3688144561620335
},
{
"name": "Background",
"score": 2.1364767908097266,
"confidence": 0.0
}
]
}
}The process can be repeated, respectively, for the SHAP explanation for the highest prediction and LIME explanations for the highest and lowest predictions.
echo "Requesting SHAP for highest"
curl -sk -H "Authorization: Bearer ${TOKEN}" -X POST \
-H "Content-Type: application/json" \
-d "{
\"predictionId\": \"$ID_HIGHEST\",
\"config\": {
\"model\": {
\"target\": \"modelmesh-serving:8033\",
\"name\": \"${MODEL}\",
\"version\": \"v1\"
},
\"explainer\": {
\"n_samples\": 75
}
}
}" \
${TRUSTYAI_ROUTE}/explainers/local/shap
echo "Requesting LIME for lowest"
curl -s -H "Authorization: Bearer ${TOKEN}" -X POST \
-H "Content-Type: application/json" \
-d "{
\"predictionId\": \"$ID_LOWEST\",
\"config\": {
\"model\": {
\"target\": \"modelmesh-serving:8033\",
\"name\": \"${MODEL}\",
\"version\": \"v1\"
},
\"explainer\": {
\"n_samples\": 50,
\"normalize_weights\": \"false\",
\"feature_selection\": \"false\"
}
}
}" \
${TRUSTYAI_ROUTE}/explainers/local/lime (1)
echo "Requesting LIME for highest"
curl -sk -H "Authorization: Bearer ${TOKEN}" -X POST \
-H "Content-Type: application/json" \
-d "{
\"predictionId\": \"$ID_HIGHEST\",
\"config\": {
\"model\": {
\"target\": \"modelmesh-serving:8033\",
\"name\": \"${MODEL}\",
\"version\": \"v1\"
},
\"explainer\": {
\"n_samples\": 50,
\"normalize_weights\": \"false\",
\"feature_selection\": \"false\"
}
}
}" \
${TRUSTYAI_ROUTE}/explainers/local/lime| 1 | The endpoint now refers to SHAP, instead of LIME. |
If the explainer needs to be configured, additional options can be added under config.explainer. For instance, to configure the number of samples used by LIME we can issue:
curl -sk -X POST -H "Authorization: Bearer ${TOKEN}" \
-H "Content-Type: application/json" \
-d "{
\"predictionId\": \"$INFERENCE_ID\",
\"config\": {
\"model\": { (1)
\"target\": \"modelmesh-serving:8033\",
\"name\": \"explainer-test\",
\"version\": \"v1\"
},
\"explainer\": { (2)
\"n_samples\": 100,
\"timeout\": 5
}
}
}" \
https://${TRUSTYAI_ROUTE}/explainers/local/lime| 1 | The model field specifies configuration regarding the model to be used. |
| 2 | The explainer field specifies the configuration of the explainer itself. In this instance, we configure the number of samples used by the explainer, as well as the maximum time (in seconds) we are willing to wait for an explanation, before it returns an HTTP time out (default value is 10 seconds). |
|
A detailed reference of all supported explainer configurations can be found here for LIME and here for SHAP. |